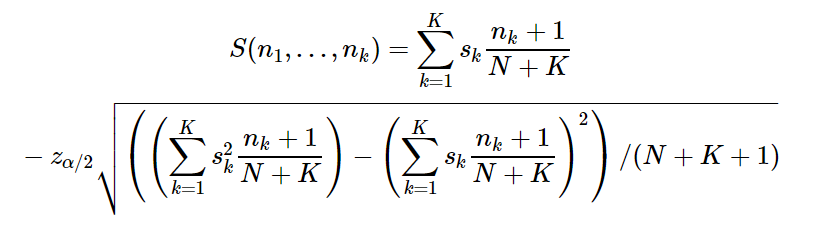Доверительный интервал биномиального распределения по методу Уилсона
В процессе изучения биномиального распределения, обратил внимание, что стандартный способ определения доверительного интервала через ±1,645SD не всегда точен. Грубо говоря, если «решка» выпала меньше, чем в 10 бросках, то, скорее всего, либо вы сделали мало бросков, либо у вас вероятность выпадения «решки» в «заколдованной монетке» сильно невелика; если np < 10, лучше воспользоваться более сложными формулами, дающими более точные оценки при маленьких p или n:
По мнению многих статистиков, наиболее оптимальную оценку доверительных интервалов для частот осуществляет метод Уилсона (Wilson), предложенный еще в 1927 году <...>. Данный метод не только позволяет оценить доверительные интервалы для очень малых и очень больших частот, но и применим для малого числа наблюдений.
Звучит заманчиво. Попробуем разобраться.
Метод Уилсона
Нижняя и верхняя граница доверительного интервала p = 1—α/2 вычисляются следующими формулами:


где p — наблюдаемая вероятность «выпадения решки», N — число измерений («бросков»), z — z-оценка (например, 1,960 для 95%-го доверительного интервала, или 1,645 для 90%-го).
Пример и калькулятор для расчета
Предположим, нам удалось прослушать 10 рандомных звонков колл-центра, и в 4 из них оператор забыл или поленился уточнить у клиента источник рекламы. Скорее всего, исходя из данной информации, операторы не уточняют источники рекламы в 40% звонков.
Однако, это очень смелое утверждение, ведь наша выборка (10 звонков) откровенно мала: для получения более точной оценки качества работы коллцентра, хорошо бы прослушать больше рандомных звонков (прослушать все звонки, очевидно, невозможно).
Но даже для выборки из 10 звонков, можно рассчитать SD биномиального распределения:

Имеем, SD = 15,49%. С вероятностью 90%, точная оценка качества работы коллцентра (доля звонков, где не выявлен источник рекламы) лежит в диапазоне 40%±1,645SD, или от 14,52% до 65,48%.
Применяя же формулу Уилсона (что уместно, так как np = 4 < 10), границы доверительного интервала уточняются: с вероятностью 90%, истинная доля звонков, где не выявляется источник рекламы, лежит в границах от 19,42% до 64,84%. SD, получается, равно 13,80%.
Калькулятор в Google Таблицах (меню «Файл» — «Создать копию»).
См. также:
«Доверительные интервалы для частот и долей», А.М. Гржибовский, 2008 (стр. 58-59)
Онлайн-калькулятор для 95%-го доверительного интервала
Калькулятор на WolframAlpha.com
Binomial confidence intervals and contingency tests (стр.4-5)
https://influentialpoints.com/Training/confidence_intervals_of_proportions.htm#wils
Wilson score interval на Википедии