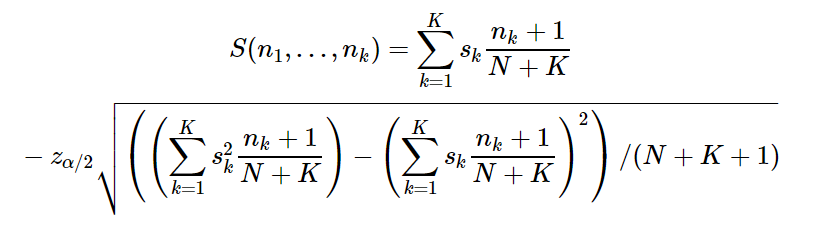Три уровня понимания выборки
В последнее время много размышлял о том, как, с точки зрения статистики, можно кратко оценить или описать любую совокупность или выборку. Пришел к выводу, что, глобально, существует 3 уровня понимания выборки.
Пруд с золотыми рыбками
Для примера, возьмем мой любимый пруд с золотыми рыбками. Вот такой:

Предположим, мы знаем вес каждой рыбки в граммах (или длину в миллиметрах, не имеет значения в данном случае):
| 96,83 | 100,84 | 97,59 | 135,46 | 89,32 | 25,72 | 71,5 | 28,7 | 100,47 | 96,08 |
| 75,74 | 90,22 | 64,58 | 101,55 | 43,38 | 109,91 | 83,22 | 115,43 | 118,84 | 56,39 |
| 99,43 | 67,46 | 99,19 | 86,85 | 53,01 | 123,29 | 95,37 | 67,57 | 123,89 | 98,91 |
| 101,96 | 157,56 | 139,5 | 89,64 | 92,31 | 175,05 | 92,29 | 124,63 | 81,35 | 107,43 |
| 86,47 | 110,03 | 144,89 | 105,25 | 137,14 | 76,28 | 102,96 | 101,95 | 90,88 | 69,02 |
| 96,76 | 110,17 | 118,66 | 100,5 | 109,23 | 40,66 | 104,43 | 113,17 | 101,9 | 66,76 |
| 107,59 | 141,11 | 71,43 | 95,73 | 52,26 | 70,67 | 70,97 | 103,66 | 135,65 | 144,62 |
| 150,26 | 130,69 | 81,31 | 163,39 | 74,22 | 83,43 | 122,14 | 122,61 | 137,46 | 53,94 |
| 29,25 | 90,83 | 119,56 | 99,3 | 34,53 | 74,02 | 120,04 | 129,32 | 124,2 | 83,37 |
| 109,94 | 70,41 | 107,63 | 107,79 | 52,74 | 79,36 | 80,28 | 72,16 | 142,41 | 64,53 |
Имея такую выборку, что мы можем сказать о наших рыбках в общем? Как кратко описать множество этих рыбок так, чтобы стало немного понятнее, с чем мы имеем дело с точки зрения статистки?
1-й уровень понимания. Среднее значение.
Проще всего было бы рассчитать среднее значение веса рыбок — в нашем случае получилось бы 96,70 г. Тогда, на первом, самом базовом уровне понимания, мы бы сказали:
— В нашем пруду водятся золотые рыбки. Их средний вес равен 96,70 г.
Верное ли утверждение? Верное. Действительно, несмотря на то, что попадаются и рыбки весом 26 г, и рыбки весом 175 г, средний вес рыбок равен 96,7 г.
Достаточно ли данной информации? Как минимум, ее достаточно, чтобы представить множество из ста рыбок по 96,7 г каждая, и, приблизительно, это дает понимание о качестве рыбок в нашем пруду. Вооружившись удочкой, мы бы шли ловить таких рыбок.
Однако, этого будет недостаточно, чтобы понять, например, как сильно рыбки различаются между собой. Потому что случайно выловленная рыбка может весить гораздо меньше, чем 96,7 г. И тут мы подошли бы к следующему, более углубленному, уровню понимания.
2-й уровень понимания. Стандартное отклонение.
Чуть более образованный человек не удовлетворился бы информацией о том, что средний вес рыбок равен 96,7 г. Он обязательно пошутил бы про «среднюю температуру по больнице» и уточнил бы, а как сильно различаются рыбки по размеру между собой?
Такое различие называлось бы стандартным отклонением (или дисперсией). Оно описывало бы величину отклонения веса случайной рыбки от среднего веса всех рыбок.
Проведя несложные вычисления, мы бы узнали, что, в среднем, вес случайной рыбки отклоняется от веса средней рыбки на 30,4 г. Стандартное отклонение (SD) равно 30,4 г.
И здесь, мы бы уточнили свое первоначальное утверждение:
— В нашем пруду водятся золотые рыбки. Их средний размер (вес) равен 96,70 г, SD=30,4 г.
Теперь случайный рыбак не просто идет ловить рыбок весом 96,7 г, а отдает себе отчет в том, что, в среднем, вес выловленных рыбок будет на 30,4 г больше или меньше среднего веса. Наш рыбак теперь морально готов к тому, что ему может попасться как маленькая, так и большая рыбка.
А, если наш рыбак еще и математик, то он прикинет, что, предполагая, что вес рыбок подчиняется закону нормального распределения (а огромное число вещей и явлений в природе и мире распределены нормально), он будет ожидать, что 68% выловленных рыбок будет иметь вес плюс-минус 30,4 г от среднего 96,7 г, или от 66,3 г до 127,1 г.
И, если наш рыбак-математик с первой попытки поймает рыбку весом, например, 146,7 г (что будет отличаться от среднего веса на 50,0 г, или 1,645SD), он будет знать, что так везет лишь одному рыбаку из двадцати, потому что лишь 5% рыбок в пруду имеют вес более 146,7 г, согласно закону нормального распределения.
Единственная проблема заключается в том, что далеко не все в жизни сводится к примеру с рыбками, или к нормальному распределению. Так как речь может идти о генеральных совокупностях, распределенных не нормально, а как-то иначе.
И тут нам придется нырнуть, вслед за рыбками, к третьему, самому глубокому, уровню понимания.
3-й уровень понимания. Гистограмма распределения.
Чтобы понять, как распределена совокупность наших рыбок, лучше всего было бы «увидеть» всю картину в виде гистограммы распределения. Поскольку далеко не всегда мы будем иметь дело с нормальным распределением, одно лишь знание о размере стандартного отклонения и степени разброса значений в нашей выборке не даст нам полного понимания и осознания нашей совокупности.
Распределив имеющиеся 100 значений веса рыбок по диапазонам от 20 до 180 г с шагом в 20 г, мы бы увидели следующую картину:
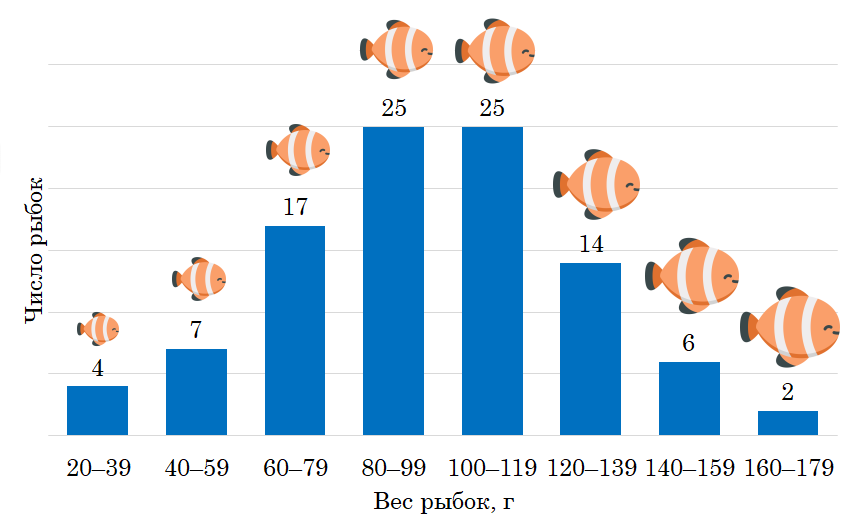
Только теперь мы получили полную картину того, какие рыбки плавают в нашем пруду. Мы словно разом прочувстовали, с чем имеем дело, увидели, насколько маловероятно выловить рыбку весом, например, больше 160 г, убедились, что вероятности встретить больших или маленьких рыбок одинаковы, а узнаваемая колоколообразная форма графика однозначно подсказала, что вес рыбок подчиняется нормальному распределению.
How much is the fish?
Мы идем на рыбалку, вооружившись полной картиной того, с чем имеем дело.
На первом уровне, уточнили средний вес рыбок.
На втором уровне, уточнили средний вес и его стандартное отклонение.
На третьем уровне, нарисовали гистограмму веса рыбок, чтобы разом увидеть портрет всех рыбок в пруду.