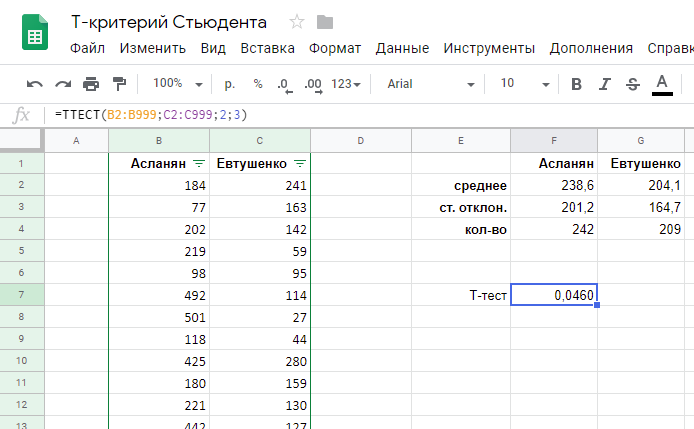
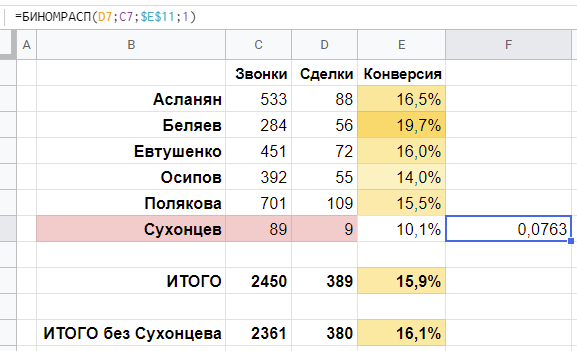
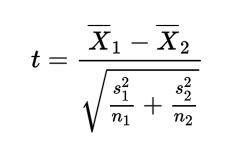Когнитивная ошибка конверсии
Любопытная особенность работы с понятием конверсия заключается в том, что, строго говоря, конверсия практически никогда не бывает определена точно.
Вот эти вот «конверсия звонка в продажу 18,4%», «CTR 3,1%», «конверсия в сделки 30%» — это всегда немного упрощенный подход, будто конверсия надежно измерена и, если и изменится, то мы это объясним объективными факторами, не допуская мысли, что изначально никаких «18,4%» и не было, а были только 38 договоров, которые мы сделали на 206 звонках, и это вовсе не значит, что их не могло бы быть больше или меньше.
Примерно, как местоположение электрона вокруг ядра атома не задается точными координатами, а лишь описывается некоторой областью, в которой он, наиболее вероятно, находится, наша конверсия — это тоже не конкретное число, а, в действительности, интервал, в котором она находится.
Расчет конверсии и когнитивное искажение
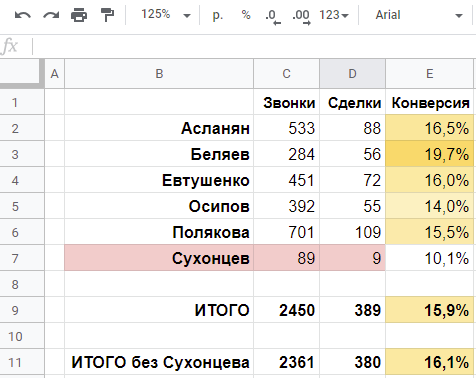
Рассмотрим вымышленный отдел продаж, в котором с этого года начали продавать новый продукт. Допустим, ммм, лимузины. Продукт не пользуется большим спросом, поэтому, пока что, данных для анализа не так много, или, лучше сказать, совсем мало:
| месяц | Заявки | Продажи |
| август | 48 | 1 |
| сентябрь | 35 | 1 |
| октябрь | 24 | 0 |
| ноябрь | 61 | 2 |
| декабрь | 32 | 0 |
| ИТОГО: | 200 | 4 |
Как видно из данных наших продаж, по итогам нескольких месяцев, мы имеем 4 сделки на 200 лидов (заявок), т. е. наша конверсия равна 4 / 200 = 2,0%
(Дополнительно, исходя из цифр пяти месяцев работы, мы можем примерно спрогнозировать 480 лидов на следующий год и, соответствнно, 480 * 0,02 = 9,6 сделок.)
В целом, на таких скудных данных ошибиться невозможно, поэтому, безусловно, такой прогноз не будет ошибочным. Однако, он содержит важное когнитивное искажение: 2,0% это не точное значение, а наиболее пока вероятное значение конверсии заявок в продажи наших лимузинов.
В действительности, конверсия не может быть определена точно. Она лежит в доверительном интервале от 0,4% до 3,6%. И в будущем году нужно прогнозировать не 9,6 сделок, а от 5 до 15 проданных лимузинов. К сожалению, определить этот диапазон точнее будет довольно самонадеянным.
Колокол конверсии
Исходя из предположения, что наша истинная конверсия стабильна, и точно равна 2,0%, мы можем прикинуть возможные варианты числа сделок на 480 лидов, ожидаемых в будущем году. Поскольку мы можем отвечать только за стабильность своей работы, но не можем учесть фактор случайности (настроение клиентов, форс мажор, случайная продажа другу гендиректора), всегда существует вероятность, что число сделок будет немного отличаться от прогнозируемых 480 * 0,02 = 9,6 сделок подобно тому, как число решек на 480 бросков монеты может немного отличаться от 240, и быть 235, 248, или, возможно, даже 223.
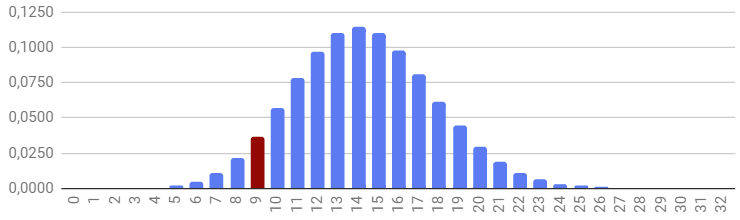
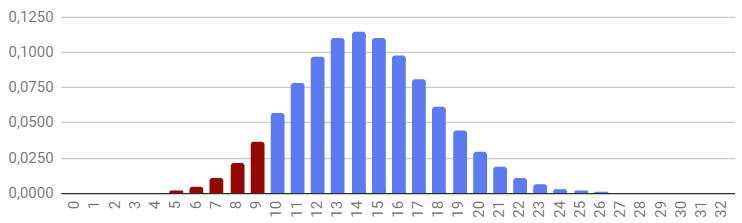
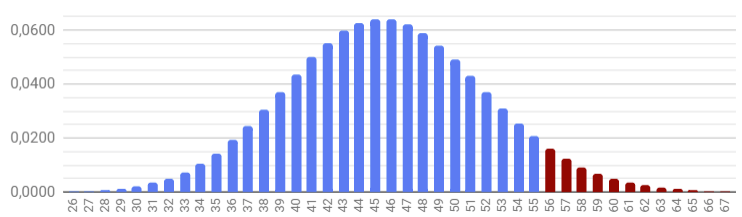
Графически это выглядит как колокол нормального распределения, где, чем дальше мы уходим от математического ожидания в 9 сделок в центре колокола, тем ниже становится вероятность сделать сильно меньше или сильно больше сделок:
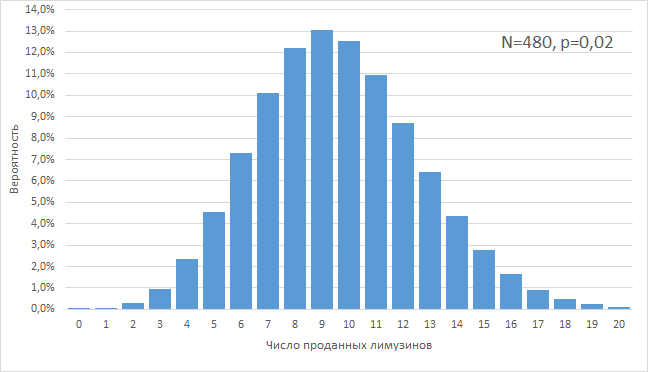
Глядя на полученный график, приходится признать, что увидеть меньше 2-х и больше 19-ти сделок практически невероятно.
Но, можно ли сузить наш доверительный интервал?
Доверительный интервал конверсии
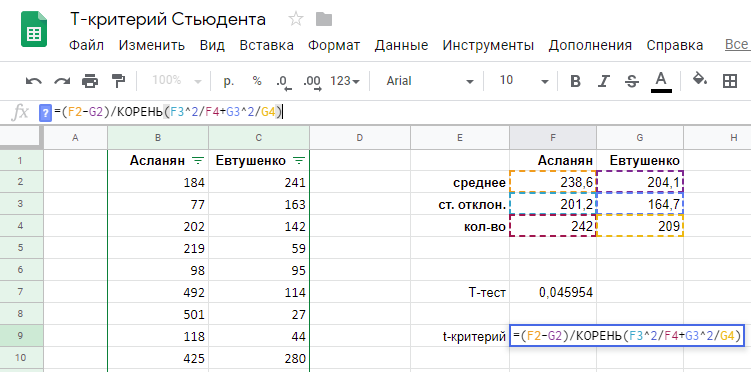
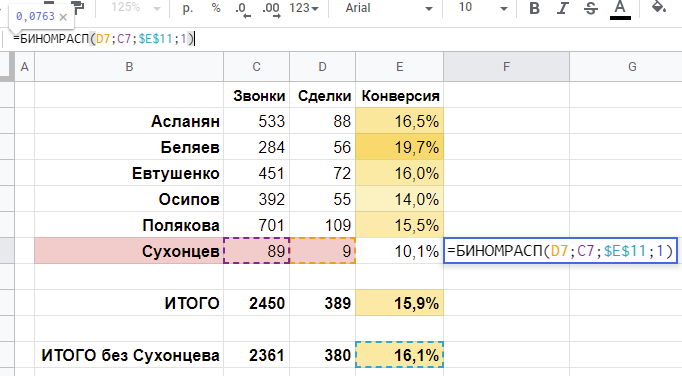
Стандартная ошибка (SD) для биномиального распределения считается по формуле:
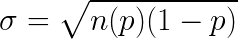
где n — это число испытаний, p — вероятность успеха.
Для наших 200 заявок текущего года имеем:
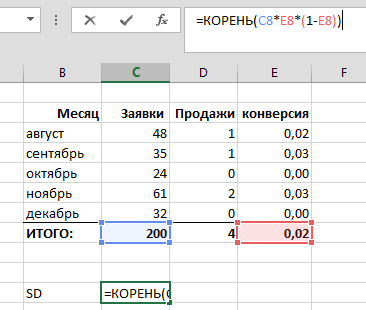
SD = 1,98 сделок. Иными словами, согласно законам нормального распределения (а биномиальное распределение — это частный случай нормального распределения), примерно в 68% случаев, работая с истинной конверсией 2,0%, мы бы попали в доверительный интервал от 2,02 до 5,98 сделок, то есть +/-1SD.
Для прогнозируемых 480 заявок будущего года получим:
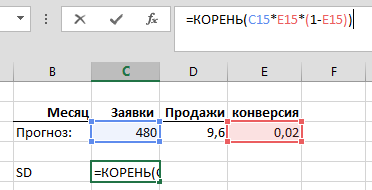
SD = 3,07 сделок. По законам биномиального (нормального) распределения, известно, что в 68% случаев продажи будущего года будут лежать в пределах +/- 1SD от математического ожидания в 9,6 сделок, а в 90% случаев — в пределах +/- 1,645SD от матожидания. 3,07 сделок * 1,645 = 5,05 сделок, иными словами, в 90% случаев, работай мы весь следующий год с конверсией 2%, мы не выйдем за границы доверительного интервала «от 4,55 до 14,65 сделок». (Примечательно, что, обратно, в 1 случае из 10, мы, все-таки, выйдем за эти границы, по-прежнему, при этом, работая с «истинной» конверсией 2%.)
Любопытно, какой шум поднимет коммерческий директор, если по итогам года мы продадим всего 4 лимузина на 480 заявок, формально показав конверсию 0,83%... и еще более любопытно, что, статистически, это происходит в 1 из 27 отделов продаж. В одном из 27-ми случаев вас увольняют за невыполнение плана продаж, хотя вы по-прежнему работаете с «истинной» конверсией 2%.
Три конверсии на границе доверительного интервала
Как же тогда относится к результатам текущего года, где мы получили 4 сделки на 200 заявок?
Первый случай, «2,00%». Его мы рассмотрели сразу. 4 / 200 = 0,02, т. е. наша конверсия равна 2%. При этом, по законам биномиального распределения, все равно есть вероятность колебаться в 90%-м доверительном интервале «+/-1,645SD», т. е., в интервале от 0,74 до 7,26 сделок на 200 заявок.
Выглядит это примерно так:
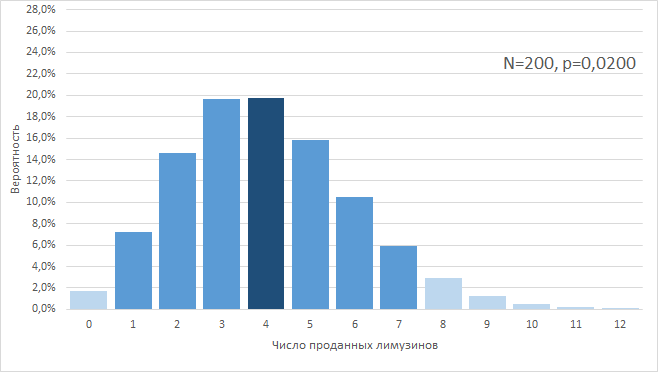
Наш результат в 4 сделки совпал с математическим ожиданием от конверсии 2,0%, хотя, в общем, он мог и не совпасть, в целом находясь в 90% доверительном интервале от 1 до 7 сделок.
Второй случай, «1,22%». В этом случае, в реальности, наша «истинная» конверсия, на самом деле, ниже, и равна, например, 1,22%. Тогда матожидание числа проданных лимузинов примерно равно 2, и нам повезло сделать 4 продажи. Степень нашего везения такова, что сделать более 4 продаж мы могли бы только в 10% случаев. Т. е., мы остаемся в поле 90%-й вероятности, хотя и находимся на границе этого поля. Еще чуть-чуть, и нам повезет слишком сильно, а пока что нам везет «в пределах разумного»:
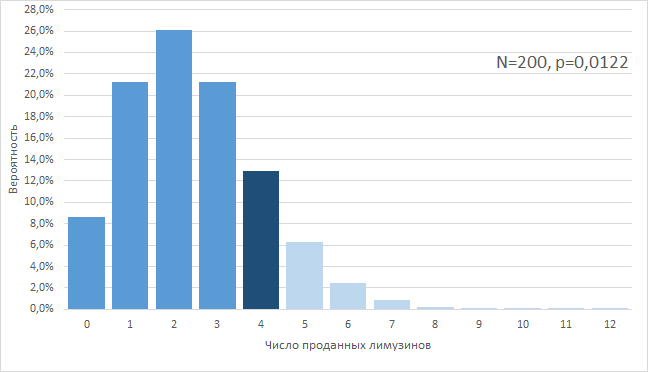
Третий случай, «3,31%». Теперь мы предположим, что в текущем году нам не везло, хотя весь год наша истинная конверсия была выше 2,0% и равнялась 3,31%. Матожидание для 200 заявок тогда равнялось бы примерно 6 проданным лимузинам, а сделать менее 4-х продаж было бы возможно лишь в 10% случаев. Тогда мы тоже остаемся в поле 90%-й вероятности, но находимся на левой границе этого поля с нашими невезучими 4 сделками.
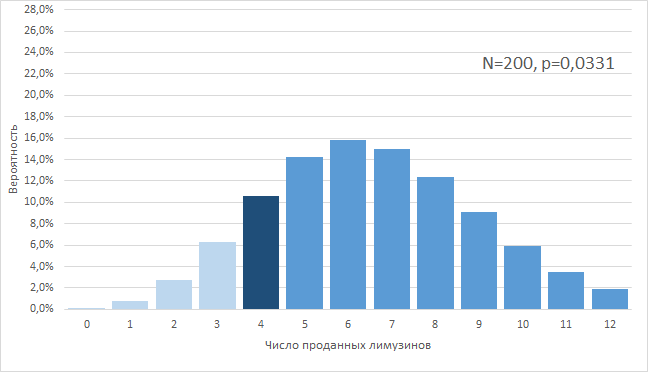
Таким образом, приходится признать: мы не знаем наверняка, какая из 3-х конверсий — истинная. Нам привычно думать, что речь идет о 1-м случае, и мы делим 4 сделки на 200 заявок, получая конверсию 2,00%. Но никто не знает наверняка, является ли текущий год обычным или необычным, везло ли нам в нем, или не везло. В 90% случаев речь могла идти как о везении, и мы работали в действительности с конверсией 1,22%, так и о невезении, когда мы работали с конверсией 3,31%. Во всех 3-х случаях вероятность сделать 4 сделки на 200 заявок не выходила за границы 90%.
К сожалению, у нас пока слишком мало данных, чтобы утверждать что-то можно было более точно.
Нужно больше данных
Логично задать вопрос — а сколько нужно накопить данных, чтобы более-менее надежно говорить о конверсии 2,0%? Попробуем постепенно увеличивать размер выборки (число заявок, и, следовательно, продаж), пока не увидим, как 90%-й доверительный интервал сомкнется вокруг значения конверсии в 2,00%:
| Заявки | Сделки | Нижняя граница 90% доверительного интервала (-1,645SD) | Верхняя граница 90% доверительного интервала (+1,645SD) | Нижняя граница конверсии | Верхняя граница конверсии |
| 200 | 4 | 0,7 | 7,3 | 0,37% | 3,63% |
| 500 | 10 | 4,9 | 15,1 | 0,97% | 3,03% |
| 1 000 | 20 | 12,7 | 27,3 | 1,27% | 2,73% |
| 5 000 | 100 | 83,7 | 116,3 | 1,67% | 2,33% |
| 10 000 | 200 | 177,0 | 223,0 | 1,77% | 2,23% |
| 50 000 | 1 000 | 948,5 | 1 051,5 | 1,90% | 2,10% |
| 100 000 | 2 000 | 1 927,2 | 2 072,8 | 1,93% | 2,07% |
| 500 000 | 10 000 | 9 837,2 | 10 162,8 | 1,97% | 2,03% |
| 1 000 000 | 20 000 | 19 769,7 | 20 230,3 | 1,98% | 2,02% |
| 10 000 000 | 200 000 | 199 271,7 | 200 728,3 | 1,99% | 2,01% |
| 25 000 000 | 500 000 | 498 848,5 | 501 151,5 | 2,00% | 2,00% |
Надо ли говорить, что получить более нескольких десятков тысяч заявок-лидов может мало какой из отделов продаж. Поэтому, приходится признать, что ставить планы продаж и принимать кадровые решения относительно сотрудников, работающих с уровнями конверсии 1-5% — это безумие, и на таких маленьких числах математика в продажах не работает.
См. также:
http://italylov.ru/blog/all/ctatisticheskaya-dostovernost-koltrekinga/