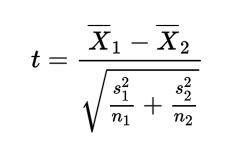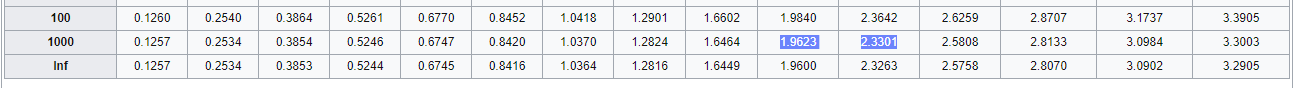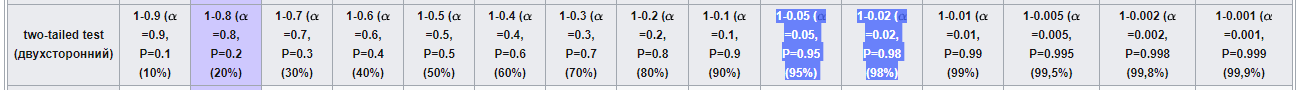Если однажды перед вами оказывались два набора похожих данных, вам, вероятно, приходило в голову задаться вопросом: насколько эти данные различаются между собой? Или, что еще более важно, наблюдаются ли статистически значимые различия между этими выборками?
Поясню, о чем идет речь.
Допустим, вы проанализировали звонки за прошедший год и обратили внимание, что среднее время звонка в первой половине дня — 2 мин 45 сек, а во второй половине дня — 2 мин 57 сек. Следует ли из этого, что звонки после обеда в среднем длятся дольше? Или это простое совпадение, и, возьми вы звонки за год до этого, вы бы увидели другую картину?
Или, например, вы замеряли уровень гемоглобина у контрольной группы до начала исследований нового лекарства, и после. Предположим, средний уровень вырос с 142,5 г/л до 147,1 г/л. Достаточно ли опираться на увеличение среднего, чтобы сделать заключение об эффективности лекарства? Или, возможно, исследование нужно повторить? Увеличив размер контрольной группы, например?
Уже из постановки вопроса очевидно, что одной разницы между средними в двух выборках недостаточно, чтобы научно подтвердить их различие.
Вот почему мы обратимся к формуле расчета и таблице значений t-критериев Стьюдента, чтобы научиться делать математически корректные выводы о статистически значимых различиях между двумя выборками. Или, другими словами, научиться видеть разницу, когда она не заметна, или игнорировать ее, даже если кажется, что она есть.
Рассмотрим вопрос на примере.
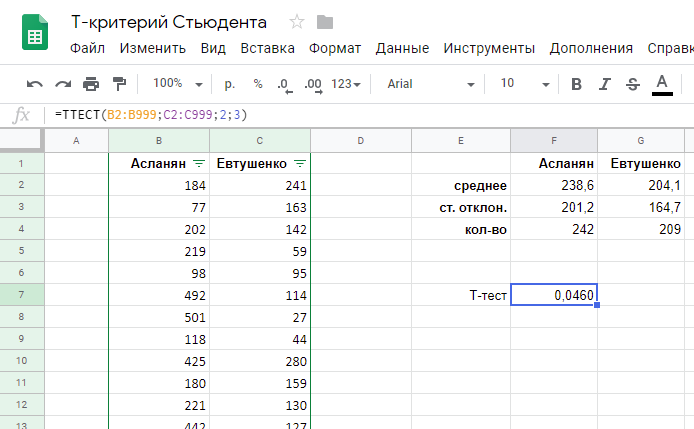
Анализ длительности звонков Асланян и Евтушенко
В вашем отделе продаж работают 2 менеджера — Ольга Асланян и Кирилл Евтушенко. Вы получили данные по длительности их разговоров с покупателями и хотите проверить гипотезу, что разговоры Асланян в среднем длятся дольше разговоров Евтушенко.
Посчитаем среднюю длительность звонка, стандартное отклонение и число звонков, которые попали в выборке.
=СРЗНАЧ(B2:B999)
=СТАНДОТКЛОН(B2:B999)
=СЧЁТ(B2:B999)
В среднем, звонки Асланян длятся на 34,5 сек дольше звонков Евтушенко. (Кроме того, разброс длительности ее звонков больше, т. к. больше стандартное отклонение. Грубо говоря, короткие и длинные звонки у Асланян найти проще, чем у Евтушенко).
Достаточно ли полученных данных, чтобы сделать вывод о правильности гипотезы, что Асланян в среднем дольше общается с клиентами, чем Евтушенко? На самом деле, нет. Всегда существует вероятность, что в выборку Асланян случайно попали более длинные звонки, а в выборку Евтушенко — более короткие. Чем больше звонков доступно для анализа (а нам достались 242 и 209 звонков, что не так уж и мало), тем более надежен результат, но он никогда не надежен на 100%.
Впрочем, надежность 100% нам и не нужна. Не ракету к Марсу запускаем. Даже если нам удастся проверить нашу гипотезу с вероятностью 90-95%, этого будет вполне достаточно для большинства случаев. Пускай мы оставим себе шанс ошибиться в 5-10% случаев, зато нам не нужно будет ждать несколько лет, чтобы накопить достаточно данных для анализа, и управленческие решения (разбор звонков с менеджером, анализ продаж, корректировки скриптов) мы сможем принять уже сейчас.
Рассмотрим два способа, как нам проверить, случайность ли, что звонки Асланян в среднем длиннее звонков Евтушенко.
Проверка гипотезы о равенстве среднего. Простой способ
И в Google Таблицах, и в Microsoft Excel, есть функция ТТЕСТ. Воспользуемся ей для анализа наших выборок.
=ТТЕСТ(B2:B999;C2:C999;2;3)
У функции 4 атрибута, идущие через точку с запятой.
- Диапазон ячеек, содержащих первую выборку.
- Диапазон ячеек, содержащих вторую выборку.
- Количество хвостов распределения. Выбираем «2», чтобы проверить наличие различий вообще, и «1», чтобы проверить, звонки Асланян длиннее, а не наоборот.
- Тип применения t-критерия. По умолчанию выбираем «3». («2» выбираем если стандартные отклонения очень близки, «1» — если, например, вы сравниваете средний балл одних и тех же учеников на начало и конец года попарно.)
Итак, Т-тест дал вероятность 0,04595, или, округленно, 4,6%.
Что же это за вероятность? В нашем примере это вероятность того, что статистически значимые различия между звонками Асланян и Евтушенко отсутствуют. Технически, это вероятность, что наша «нулевая гипотеза» («нет разницы между выборками») была верна, а «альтернативная» («Асланян общается с покупателями дольше Евтушенко») — неверна.
Оставшиеся 95,4% составляют вероятность того, что между выборками есть статистические различия, и «альтернативная гипотеза» о различиях между выборками верна.
Вывод: с вероятностью 95,4% Асланян, действительно, в среднем общается с клиентами дольше Евтушенко. (С вероятностью 4,6% статистически значих различий между их звонками нет).
Проверка гипотезы о равенстве среднего. Сложный способ
Сложный способ будет состоит из двух этапов: расчет t-критерия Стьюдента и сравнение полученного значения t-критерия с контрольным.
На первом этапе рассчитаем t-критерий Стьюдента по следующей формуле:
X1 и X2 — средняя длина звонков в первой и второй выборке (238,6 сек и 204,1 сек)
s1 и s2 — стандартные отклонения первой и второй выборок в квадрате (их дисперсии, другими словами) (201,22 и 164,72 для наших выборок)
n1 и n2 — число звонков в первой и второй выборках (242 и 209 звонков)
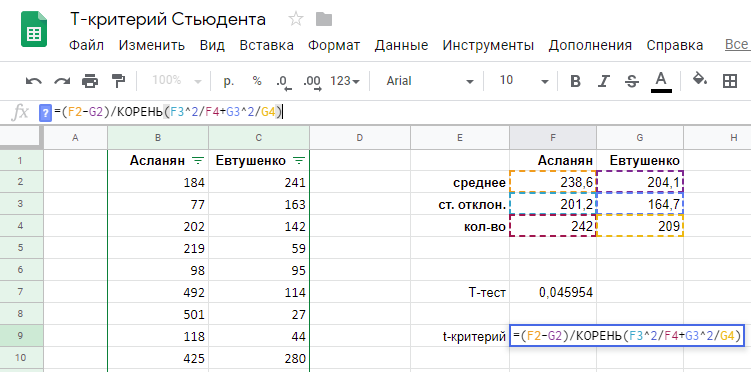
Воспользуемся листочком бумаги и калькулятором, или же посчитаем все прямо в Google Таблицах:
=(F2-G2)/КОРЕНЬ(F3^2/F4+G3^2/G4)
t-Критерий равен 2,0014.
Осталось разобраться, что делать с вычисленным значением нашего t-критерия.
Но перед этим посчитаем число степеней свободы по формуле n1+n2-2:
242 + 209 — 2 = 449 степеней свободы
Воспользуемся теперь таблицей коэффициентов Стьюдента из Википедии, найдя строку, соответствующую нашим 449 степеням свободы.
В нашем случае, строки именно для числа 449 нет, зато несложно заметить, что значения для 100 и 1000 — ближайших подходящих строк — отличаются на сотые доли, поэтому для большого числа степеней свободны подойдет любая строка.
Наше значение 2,0014 находится между 1,9623 и 2,3301: 1,9623 < 2,0014 < 2,3301
В шапке таблицы это соответствует 95%-му и 98%-му квантилю распределения Стьюдента, т. е. мы захватили 95%-й квантиль, но не захватили 98%-й:
Если расчетное значение t-критерия Стьюдента больше контрольного, значит, «альтернативная гипотеза» верна с соответствующей вероятностью (95%), и выборки статистически различаются.
Если бы мы получили значение t-критерия больше, чем 2,3301 (98%), мы бы могли говорить по правильности «альтернативной гипотезы» уже с 98%-й вероятностью. Аналогично, если бы мы получили значение t-критерия меньше, чем 1,9623 (95%), но больше 1,6464 (90%), мы бы говорили о правильности гипотезы на 90%.
Вывод: расчетное значение t-критерия Стьюдента 2,0014 соответствует, по меньшей мере, 95% уверенности в том, что между выборками есть статистически значимые различия, и звонки Асланян, действительно, в среднем длиннее звонков Евтушенко.
Наша «альтернативная гипотеза» получила 95%-ое подтверждение, мы можем быть уверены в результате и принимать решение о дальнейшей работе с полученный информацией.
Полезные ссылки
http://www.evanmiller.org/ab-testing/t-test.html