Голосовой робот KupiVIP, угадываем размер выборки
В статье «Кейс: заменили на Black Friday колл-центр KupiVIP роботом, и только 5 человек из 5000 поняли, что общаются с нейросетью» на vc.ru меня, среди прочего, не могла не заинтересовать фраза, где автор рассказывает о росте конверсии с 6% до 8%:

Естественно, я задумался, на каком же объеме звонков был зафиксирован данный рост конверсии, и достаточен ли был этот объем, чтобы можно было достоверно утверждать, что голосовой робот эффективнее живых операторов колл-центра.
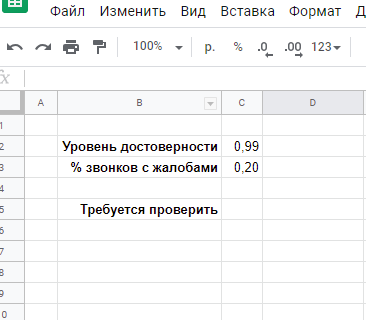
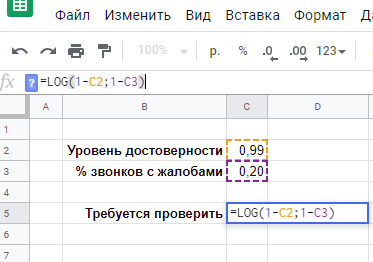
Точно вопрос можно было бы сформулировать, например, следующим образом: какой минимальный объем звонков требуется сделать, чтобы с уровнем достоверности, например, 95% зафиксировать рост конверсии с 6% до 8%?
Строим эксперимент в Excel
Попробуем выписать имеющиеся данные в Excel. Для дальнейших расчетов нам понадобится параметр «число звонков» — предположим пока, что и робот, и операторы сделали по 1000 звонков, прежде чем были получены конверсии 6% и 8%:

Вообще, налицо обычный А/Б сплит-тест, и далее нам нужно будет пройтись по его алгоритму для получения Z-оценки и расчета p-значения.
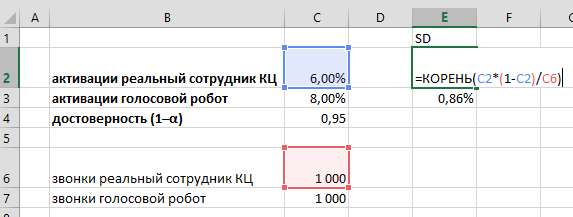
Рассчитаем стандартные ошибки (SD, или σ) для обеих конверсий и стандартную ошибку разницы этих конверсий. Формула для расчета стандартной ошибки конверсии:

где p — конверсия (6%, например), n — размер выборки (1000 звонков). Считаем в Excel:
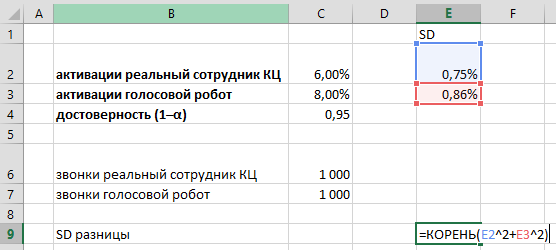
Стандартная ошибка разницы конверсий — считаем по формуле:

где σ — это стандартная ошибка каждой из конверсий A и B (оператор и робот). В Excel посчитаем ее чуть ниже:
Насколько разница между конверсиями A и B больше, чем стандартная ошибка этой разницы? Это соотношение называется Z-оценкой. В Excel считается совсем просто:
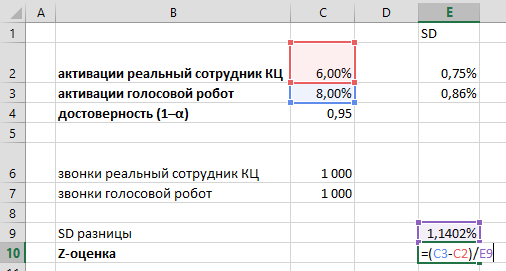
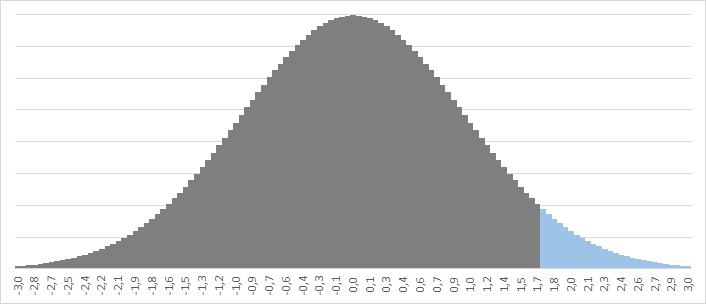
Итак, Z-оценка = 1,7541. На графике нормального распределения это соответствует 96%-му персентилю, то есть, вероятность, что Z-оценка случайно окажется выше 1,7541 составляет порядка 4% (иными словами, 96% площади под колоколом нормального распределения не выходят за пределы +1,7541 стандартных отклонений):
Откуда мы взяли именно 96%? Точное значение вероятности, p-значение, вычисляем по формуле:
=НОРМ.РАСП(1,7541;0;1;ИСТИНА)
P-значение = 96,03%.
Итак, промежуточный вывод: если на выборке в 1000 звонков в каждом из двух случаев мы обнаружили конверсии (активации промокода) в 6% и 8% звонков, то мы на 96% уверены, что эта разница не случайна. (Остается 4% вероятности, что обнаруженная разница — случайность. Тогда, возможно, конверсия вообще одинакова и равна, например, 7%. Сделай мы больше звонков, разница вскоре сошла бы на нет).
Эксперимент минимального размера
Однако, вернемся к первоначальной задаче.
Мы не хотели убедиться, что 8% больше, чем 6%, да и цифра 1000 звонков для робота и операторов была выбрана наугад. Мы хотели рассчитать минимальное количество звонков, чтобы с уровнем уверенности 95% зафиксировать статистическую значимость разницы между 8% и 6%.
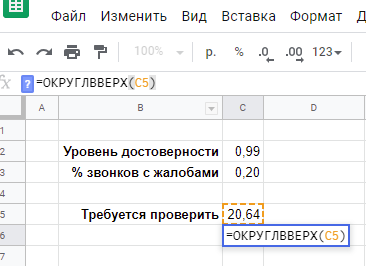
1000 звонков нам оказалось точно достаточно. Теперь нам остается уменьшать это число до той поры, пока p-значение не пересечет границу 95%. (По формуле нормального распределения, кстати, это будет соответствовать Z-оценке, равной 1,6449 — попробуйте проверить.)
В теории, наверное, можно было бы вывести большую формулу для расчета такого n, при котором p-значение будет равно 0,95. На практике, быстрее окажется вручную подобрать минимальное n. Или, еще лучше, воспользоваться в Excel инструментом Данные — Анализ «что, если» — Подбор параметра:
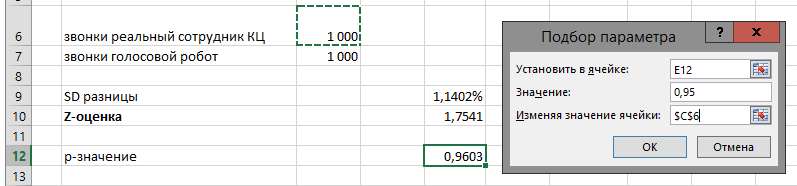
(Убедитесь только, что число звонков робота ровно то же самое, что и число звонков оператора, т. е. вы указали =C6 в ячейке C7).
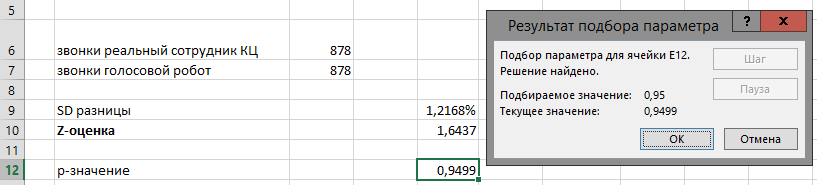
Выводы
Итак, мы вычислили минимальные условия эксперимента для оценки эффективности голосового робота для KupiVIP.
Нужно не менее 878 звонков в каждой из двух групп, чтобы с уровнем достоверности 95% подтвердить наличие разницы между 6% активаций промокодов в контрольной группе (реальные сотрудники) и 8% в тестовой группе (голосовой робот).
(Единственное, ни 6%, ни 8% не дают целого числа активаций на выборке из 878 звонков, и, в реальности, конечно, цифры будут другие, причем число звонков в двух группах вообще может быть различным. Но, на самом деле, это не имеет большого значения, т. к., наверняка, в статье были приведены округленные значения конверсий).